Table of Contents
This chapter describes how to setup ThinLinc with High Availability (from now on referred to as "HA") for the VSM server. Since the VSM server service handles load-balancing and the session database, it can be problematic if the machine fails. ThinLinc HA provides protection for this service against the single point of failure that the hardware running the VSM server normally is.
The basic principle behind this setup is to have two equal machines, both capable of running VSM server. If one of the machines goes down for some reason, the other machine will take over and serve VSM server requests with no or short interruption of service.
Note
The HA functionality provided by ThinLinc provides synchronization of the ThinLinc session database across two VSM servers. The software used by these machines to implement failover is not part of ThinLinc, and must be installed and configured according to your requirements. The industry standard for doing so on Linux is provided by the Linux-HA project; see http://linux-ha.org for more information.
In a standard ThinLinc setup, there is a single point of failure - the machine running the VSM server. If the VSM server is down, no new ThinLinc connections can be made, and reconnections to existing sessions can't be established. Existing connections to VSM agent machines still running will however continue to work. A ThinLinc cluster of medium size with one machine running as VSM server and three VSM agent machines is illustrated in Figure 6.1
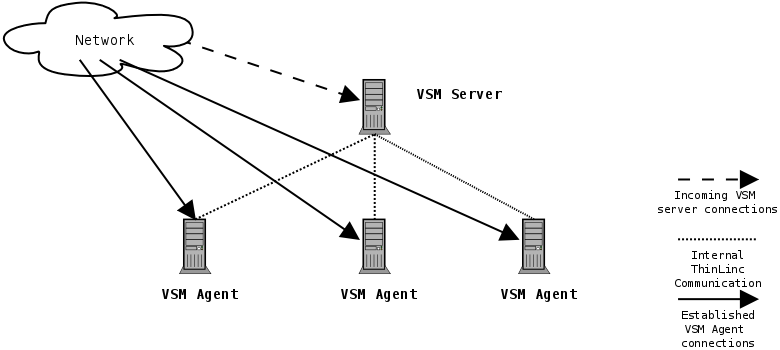
Here the incoming connections are handled by the VSM server which distributes the connections to the three VSM agent machines. If the VSM server goes down, no new connections can occur. The VSM server is a single point of failure in your ThinLinc setup.
In order to eliminate the single point of failure, we configure the VSM server in a HA configuration where two machines share the responsibility for keeping the service running. Note that ThinLinc's HA functionality only handles the parts of your HA setup that keeps the ThinLinc session database syncronized between the two machines. Supplementary software is required, read more about this in Section 6.1.3, “ Theory of Operation ”.
When ThinLinc as well as your systems are configured this way, the two machines are in constant contact with each other, each checking if the other one is up and running. If one of the machines goes down for some reason, for example hardware failure, the other machine detects the failure and automatically takes over the service with only a short interruption for the users. No action is needed from the system administrator.
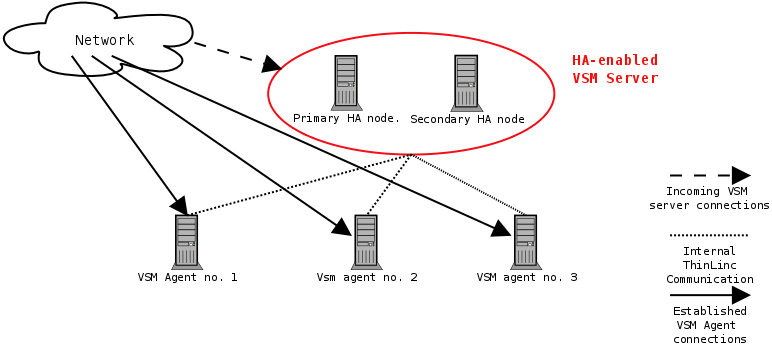
In a HA setup, as illustrated in Figure 6.2 two equal machines are used to keep the VSM server running. One of the machines is primary, the other one is secondary. The primary machine is normally handling VSM server requests, but if it fails, the secondary machine kicks in. When the primary machine comes online again, it takes over again. That is, in normal operation, it's always the primary machine that's working, the secondary is just standby, receiving information from the primary about new and deleted sessions, maintaining its own copy of the session database.
Both machines have an unique hostname and an unique IP address, but there is also a third IP address that is active only on the node currently responsible for the VSM server service. This is usually referred to as a resource IP address, which the clients are connecting to. ThinLinc does not move this resource IP address between servers, supplementary software is required for this purpose.